主題介紹
近年來隨著
AI技術發展越來越成熟, AI已經可以被用在非常多的 領域 ,幫
助人們解決各式各樣的問題。 在遙測及公共事務領域上,同樣也可以借助 AI模
型的幫忙,協助作業人員迅速的處理及分析資料。 此篇將 嘗試 運用 卷 積 神經網路
(CNN)中 ResUNet的方法 由 SuperDove衛星影像 訓練模型 進行台灣地表的建物
偵測,並搭配政府出版的土地利用 圖資 (1/25,000經建版地形圖數值資料檔 ),使
模型 能 迅速找出未被列入資料的建築物並標記出來,幫助從業人員迅速的找出違
建可能發生的所在地,擺脫以往可能需要直接由一塊塊 小面積的影像進行人工判
斷,非常費時且又耗費勞力,運用此方法可以很有效率且減輕人員的負擔。
卷積神經網路模型: U-Net
U-Net是基於 Autoencoder所延伸出來的方法,常被用於影像分割的任務上,
其最早是運用於醫療影像上,透過 U-Net模型 找出斷層掃描影像中人眼難以分辨
的腫瘤區域,並有良好的結果,在當時可以說是跨時代的進展。如今在此將它用
於衛星影像上,得以找出影像上的房屋所在區域,可以有效率地進行下一步的分
析。
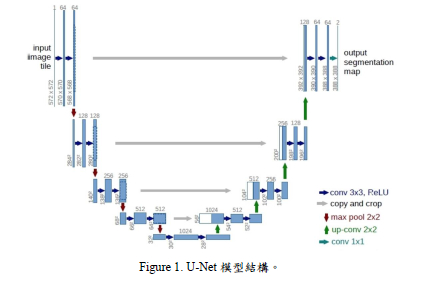
U-Net透過近幾年的不斷演進, 已經發展出不同的版本,但不變的是其皆是
由 Encoder和 Decoder二部分所組成。 U-Net顧名思義,它的模型形狀正是類似
U字形,如 Fig.1所示。在 Encoder部分是不斷由 卷 積層 (Convolutional Layer)進
行特徵萃取,而 Decoder則是由萃取出的特徵再經過 卷 積 層和上採樣層
(Upsampling Layer)還原成相同大小的分類影像。在此次是利用 ResUNet模型,
每個區塊皆是由殘差結構 (Residual Block)組成 (Figure 1. U-Net模型結構。 Figure 1),殘差結構 可以加深模型且不致於造成訓練困難,非常適合運用在這次的任務
上。
訓練資料集
此次的訓練資料是來自 PlanetScope的衛星影像, PlanetScope是一個有著上
百顆的立方衛星群所組成,其衛星也被稱作為 Dove衛星 (有些稱為 Dove-R或
SuperDove)。它提供大量且高解析度 (3m)的地球觀測數據,首顆從 2014年升空
並運行至今,提供 4-8種波段的資料 ,這次是使用 SuperDove衛星提供的影像,
包含 8個波段,空間解析度為 3m。
另一方面,在地真
(Ground Truth)的資料是利用「內政部國土測繪中心國土測
繪服務雲」網站內的「 1/25,000經建版地形圖數值資料檔」中所提供的台灣地表
房屋區域,將其視為房屋的標記資料。藉由衛星影像及經建版地形圖數值資料檔
相互搭配 ,選出地形圖中的 17張 區域 (Figure 2),使其二者的每塊 地區 進行地理
座標對齊並分割成大量 256x256的子影像,因而得以形成訓練 U-Net所需的訓練
資料 共有 4,608張 影像作為訓練樣本,其中 80%作為訓練集 (Training Set),而剩
下 20%則做為訓練過程中的驗證集 (Validation Figure 3為其中一張 訓練用的
圖幅及建物範圍 作為範例 。
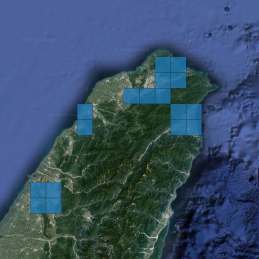
Figure 2. 根據經建版地形圖選出的 17張建築物較多之區域 (圖中藍色範圍 ),將
搭配 SuperDove影像作為 U-Net模型的訓練資料。

Figure 3. 圖幅編號 97224NW的 SuperDove衛星光學影像 (左 )及其對應建物範圍(右 )。
訓練策略
由於訓練需要不間段的 GPU運算資源,因此整個訓練過程是於外部電腦進
行訓練,訓練後的權重將保存下來以利接下來的測試。 訓練 設定為 100個 epochs初始學習率
初始學習率(learning rate)為為0.001,損失函數,損失函數(Loss Function)為為Binary Cross Entropy,,且若每且若每5個個epochs中計算中計算出驗證集的損失函數數值沒有在更進一步增加的話即出驗證集的損失函數數值沒有在更進一步增加的話即視為模型訓練到達比較平穩的階段,因此若成立則會將學習率降低視為模型訓練到達比較平穩的階段,因此若成立則會將學習率降低1/2,使模型,使模型逐漸收斂,不再讓它有大幅度變動的可能。逐漸收斂,不再讓它有大幅度變動的可能。
成果展示
接下來為選出經建版地形圖中的6個區域進行測試,測試的結果將以IoU(Intersection over Union)做為評估指標 ,可參考 Figure 4的示意圖 和 IoU其表達式如下:
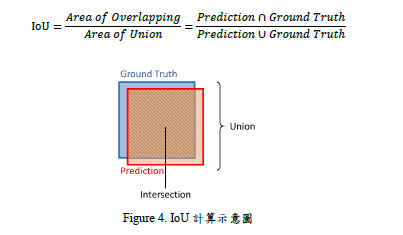
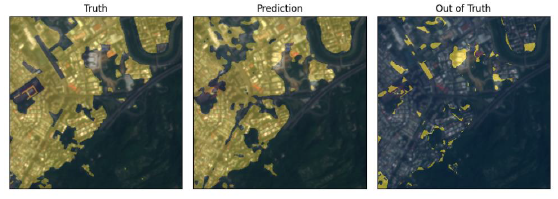
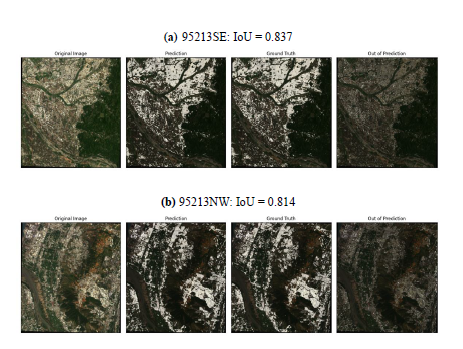
IoU是以模型預測和地真資料的交集與聯集計算出來的數值,其數值會在 0至 1之間,愈接近 1代表模型預測的愈準確,反之則表現不優。 Fig.3中由左邊
至右邊依序為衛星的 RGB影像、模型預測結果 (亮白部分 )、 地真之房屋區域 (亮
白部分 )及 U-Net模型多預測的部分, 可以由 Fig.3中看出, 在所選的測試影像中
U-Net都得到頗高的 IoU數值 ,其約落在 0.7-0.8左右 ,不過對於 房屋比較稀疏
的區域 IoU數值便不會那麼高。回到偵測違建的方面,若是將U-Net模型預測為房屋的部分扣除已知有登錄
在地真的房屋資料,即得到模型認為是房屋,但 並不存在於政府登入資料內的區
域 (也就是 Figure 5中的最右邊的圖 )。若將某區放大來看便可以看出模型預測是
房屋但卻不在地真內的範圍,這些區域因為不登記在政府的經建版地形圖的房屋
資料內,因此即有可能是違章建築,透過此方法可以迅速且有效率的找出特定範
圍有可能為 目標的地方,最後再簡單地交由人工篩選,便可以以有效率且比較不
費勞力的方式達成找到違建房屋的目標。


單獨放大其中圖幅號
97233SE和 97224NW的影像 (Figure 6-Figure 7),此 二
影像位於新北市的汐止區 及新店文山區 可以 看出由 U-Net預測的結果與實際地
真有所差別,將預測結果減去政府圖資的建物資料後取其值為正的地區,也就是
模型多 預測的區域,這些不在原始地真資 料內的建物便極有可能為違建 或未被登
記至地籍資料內 ,可以將這些地區標記出來以利進一步的分析或是實地考察等。

Figure 6. 位於新北市汐止區的局部區域放大結果 。左圖為政府圖資的建物區
域,中圖為模型預測為建物的地區,右圖為模型預測減去政府圖資,即為有可
能是為違建或未登入進資料之區域。
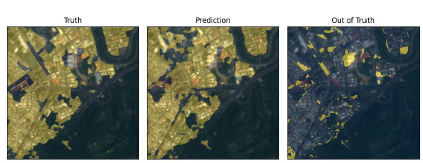
Figure 7. 位於台北市新店、文山區的局部區域放大結果 。左圖為政府圖資的建
物區域,中圖為模型預測為建物的地區,右圖為模型預測減去政府圖資,即為
有可能是為違建或未登入進資料之區域。
總結 與展望
透過這次的訓練與測試結果,可以看出模型絕大多數可以找出建物的範圍,
雖然偶會有誤判,但是可以提供 影像內有可能的違建潛在區域,搭配高解析度的
衛星影像便可以再由從業人員迅速的篩選,最後即可找出是為違建 或是未登錄進
資料 的地區!
目前由 於 公 開 資 料 只 有 「 1/25,000經建版地形圖數值資料檔 」 檔案 當 中 有
些 馬 路 也 被 當 成 建 物 進 行 訓練 而 更精細的 土 地 資 料 可 能 需 要 花 上 一 大 筆 錢 才能
取 得 。 不 過 若 是 能 用 更 精 細 的 建物 資 料, 搭 配 更 高 解 析 度 的 影 像, 理論 上 可 以 訓
練 出 更 準 確 的 模型 以 及 更 好 的 結 果。
附錄
Building Detection.ipynb