
超解析度成像 (Su per resolution imaging 主要應用演算法來提高影像上
的解析度,可以將圖片細節優化來提升人眼或是腦的辨識能力。目前超解析技術
可以用在一般照片、手機相機 或是醫學上的斷層掃描等科技上,存在影像的事物
上都可以派上用場,應用範圍極廣。
目前發展中的超解析影像主要是透過 AI 的技術實現,
由訓練建構好的類神經網路模型來達成想要的結果。
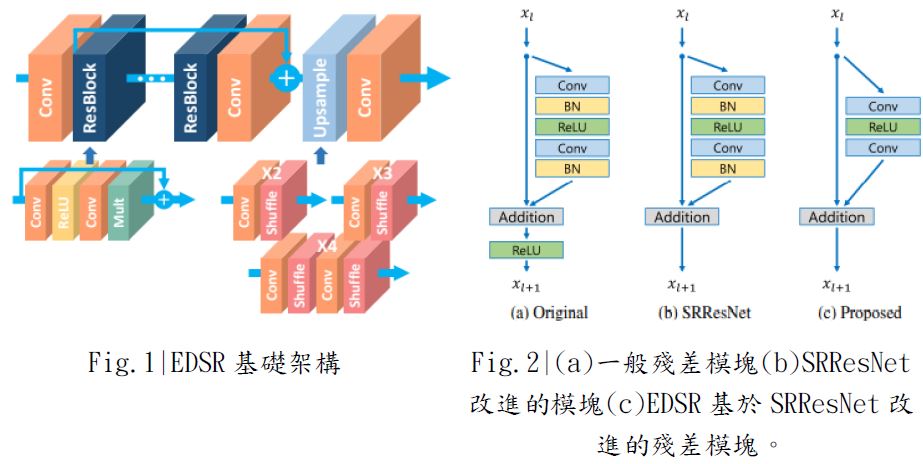
Enhanced Deep Super Resolution (EDSR) 即是
在2017 年提出的超解析模型 ,它建構在ResNet的基礎上,
透過改良前一代的超解析模型SRRe sNet,
移除了在殘差結構 (Residual Block)中認為不必要的神經層,
進而形成目前的EDSR模型。 Fig.1 為其架構的簡圖以及Fig.2為一般殘差
模塊和 SRRe sNet 改進的殘差模塊與本篇模型EDSR提出的基於前二者而再改進的殘差模塊 。
這次希望可以透過超解析影像的方法,將此技術應用於 衛星影像上,
使得在影像上提高解析度,讓肉眼或電腦能更好辨識地表物體之外觀,
在未來能更進一步的應用於其它方面。
在此之前,EDSR 作者主要用 DIV2K 資料集進行訓練與測試,
DIV2K是一個公開給超解析影像的類神經網路作為訓練用的資料集,
但其影像內容主要以風景、建築或是動物為主,
我認為若是直接套用先前訓練完成的模型至衛星或空拍影像上效果可能並不會太好。
因此,試在Kaggle網站上選用 DeepGlobe Road Extraction Dataset
此資料集的衛星影像作為訓練樣本,
重新訓練EDSR並期望能套用於其他衛星影像中並取得不錯的效果。
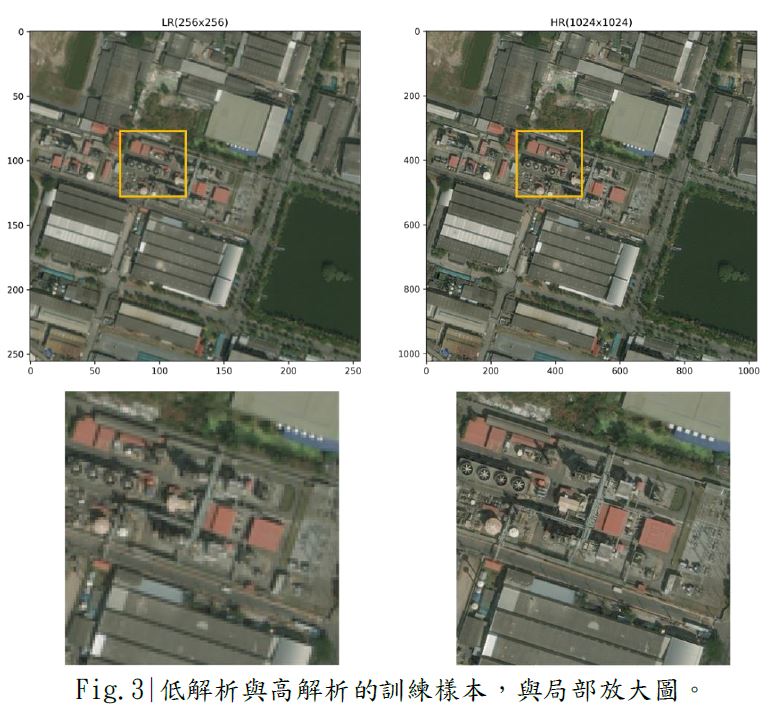
此資料集的衛星影像是只有 RGB 三個波段的光學影像,
每一幅大小皆為 1024x1024 pixels,將此高解析影像(High Resolution, HR)
作為EDSR模型的目標 (Target),並對影像降解析至 256x256 pixels,
為低解析版本 (Low Resolution,LR) 以作為模型的輸入 (Input) 。
Fi g. 3 則為訓練集的其中一張 LR與HR影像的樣本。
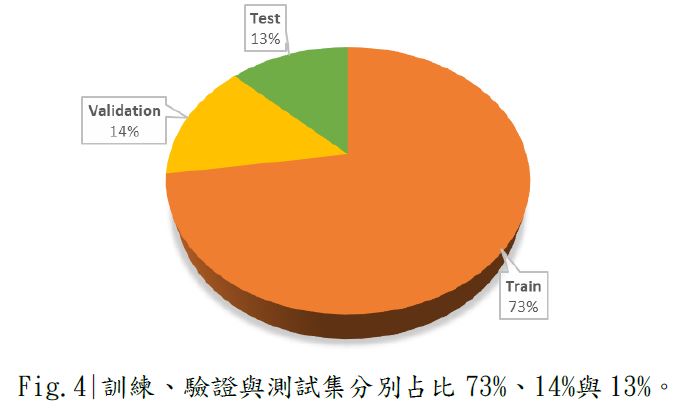
此資料集總共有 8570 幅衛星影像,網站上的分類將其中 6226 幅作為訓練集
(Train Set) 、其餘 1243 與 1101 幅影像分別作為驗證集 (Validation 與測試集 (Test Set)
訓練過程需耗費電腦大量運算及時間,不過 kaggle 網站會提供 30 40 hrs/week
不等的時間可以任意使用雲端GPU功能,因此 EDSR 模型訓練過程這部分
是使用此雲端資源完成的。將 EDSR訓練30個循環 (epochs ),每循環約耗費
10-11 分鐘左右,整個訓練過程約花 5-6小時完成,完成之後將模型之權重
(weights 保存下來進行接下來的測試。)
為了評估 EDSR 產出的高解析影像之成效,因此另外選用 2 種評估方法作為指標

經過上述流程,花費幾小時的訓練,而將 EDSR 模型分別測試自身訓練集與
LandSat-8 衛星影像的二種資料,可以在短短幾秒鐘產出解析度放大四倍的超解析影像,
EDSR 得到的 PSNR 與 SSIM 分別為 28.65 dB 與 0.739 且二種指標都高於
直接用雙線性與雙立方插植法所輸出的圖片。若放大由肉眼觀察,可以看到尤其
在直線的輪廓上,低解析度版本會有鋸齒狀的效果,二種插植法 有時候仍然很明顯,
但若用 EDSR 擬合過後直線部分便會變得非常清楚,鋸齒狀效果消失
總的來說,EDSREDSR在超解析成像中取得好的結果在超解析成像中取得好的結果,
未來必定能大大增加應用性,未來必定能大大增加應用性。