
近年來,世界各國不斷在制定國際法打擊非法、隱匿、管制外的船隻,除了法律與條文的制約之外,一套對於海洋遙測的識別技術是不可或缺的。試想: 若是有監視攝影機沒有警察,法律條文再滴水不漏也毫無用武之地。2012 年資料開放政策推動之後,國際上漸漸有許多的衛星資料穩定且無償的開放給世界各國進行海洋環境監測或研究的需求。台灣為海島國家,對於船舶的有效監控與管理實為發展智慧海運刻不容緩的要務。近年來隨著深度學習網路的蓬勃發展,許多應用深度學習於目標物辨識也獲得很好的成果。
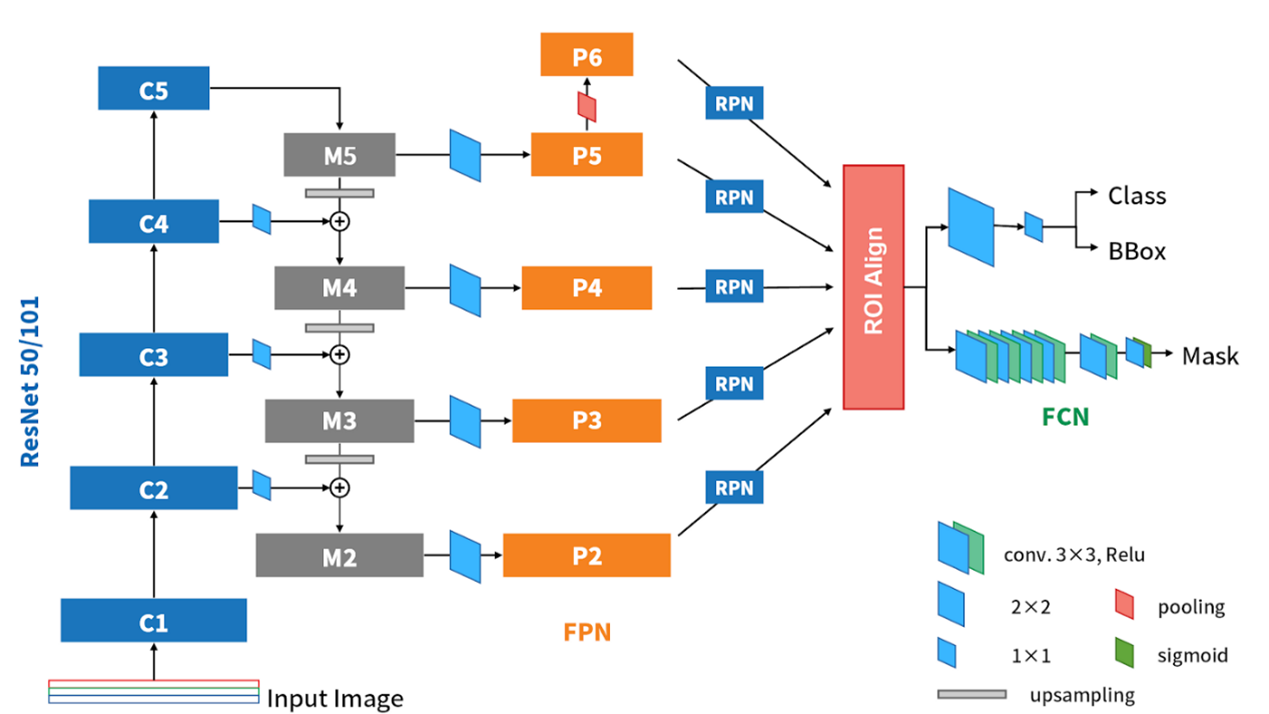
基本上我們可以看到基本上他就是Faster R-CNN的進化版,再加上一個分支來處理instance segmentation(也就是mask)。這裡頭很多熟悉的地方像是之前有介紹過的FPN、RPN、FCN,還有一個從ROI Pooling演變而來的ROI Align。因為上述這些NN,基本上都與之前介紹過的很相似,所以以下我們就針對Mask R-CNN的改變,以及它在檢測上的新分支來做說明。
> FPN
在FPN的部份,由ResNet (or ResNeXt) 50/101的C2~C5 block可以獲得P5~P2的feature map,不過記得FPN原文中,還在P5上再pooling一次,得到更小(粗糙)的feature map P6,來對實際影像中更大的物體提出proposal。而P6因為只是拿來提出proposals的,實際上在切feature map時,不會在P6上切(FPN paper Eq-1),所以P2~P6會進RPN,而P2~P5才會進後面的detector部份。
> ROI Align
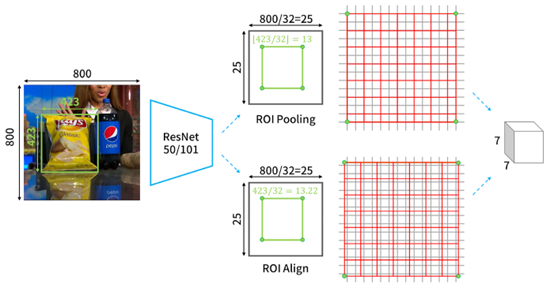
Fig-02
ROI Align最重要的改良點就是對於位置的描述。若我們以綠色框與角點代表物體的邊界框和位置,則可以看到在之前的ROI Pooling中,總共需要經過兩次的取整。第一次是物件在原圖上要映射到feature map上時,邊界框的尺寸和位置的取整(如Fig-02中的上路),第二次是ROI準備要進入n×n的ROI pooling時,分割成n×n網格的取整(如Fig-02中的上路)。這兩次取整都會對預測出來的邊界框反推回原圖尺寸時,產生不小的偏差。因此如果直接在原有的架構上加上mask分支,就會發現mask和物體錯位的情況很嚴重。
ROI Align就只是使用比較優雅的方式,不直接取整,就能獲得很好的進步。可以看到以邊界框和位置的部分來說,我們可以看到在Fig-02的下路中,綠色點是沒有恰落在灰色網格上的。而要做pooling的時候,也是採整個ROI均分成n×n網格(以下稱bins)的方式進行pooling。不過因為如此,就會在每個bin中都含括到若干個feature map上的像素,所以作者採用雙線性內差的方式來進行插值才做pooling。詳細地說,以Fig-03為例,在feature map上,會取當前ROI中的某個bin中的鄰近4點,做雙線性內插,之後在對每個bin中的4個’’。’’進行pooling的動作,來提出ROI。值得一提的是,作者試驗出以4點做內插效果最好,但是只有1個點的表現也幾乎有一樣的水準。這顯示對於定位結果的好壞,內插考量的點數並不是太重要的因素。重要的點還是在取整造成的影響,特別是今天對於辨識的物體若在影像中是小的,則些微的偏差都對物體定位的誤差造成很大的誤差貢獻。

Fig-03
> Loss
Mask R-CNN的loss function是
![]()
Eq-01
其中,Lcls和Lbox的部份和Faster R-CNN是一樣的。至於在mask分支的部分,輸出是m×m×K,m是mask的解析度,K是class數量。以COCO資料集來說,K就是80個類別。在Mask R-CNN中,mask的分支雖然也是採用FCN的設計,但是其活化函數和損失函數卻並不是FCN常見的softmax和cross entropy的組合,而是採用sigmoid,和average binary cross entropy。並且,mask分支會對進來的ROI給出所有類別的mask(也就是K個mask),卻不是每個mask的損失都會計入Lmask中。而是根據分類分支所判斷的結果是k類,才計算mask分支上第k類的mask的loss,計入Lmask中。
> Instance Segmentation
那為何Mask R-CNN可以做到很好的instance segmentation,而不是像一般採用FCN方法的模型,只能產生semantic segmentation或是有明顯瑕疵的instance segmentation呢?第一點是因為Mask R-CNN是平行判斷類別和mask的,分支網路是獨立被訓練出各自的參數,而且是一次一個ROI來根據其類別判定的結果,選擇要使用的mask,所以個體之間因為是不同的ROI所以可以很容易就獨立,mask也可以獨立。但是FCN的方法中,判斷類別和mask是一起來的,這樣的機制會使得不同類別和mask之間的競爭,也因為一個類別一個mask的設計,無法獨立個體。另一個作者說是很重要的因素是,Mask R-CNN 的激活函數和損失函數是採用sigmoid與average binary cross entropy,如我們在前一節講到的。這樣的設計在作者的實驗中發現可以避免原本作法會產生的mask跨類別競爭的不利影響,而可以為mask的結果帶來很好的instance segmentation的結果,也就不會出現FCIS對於重疊物件會畫出奇怪的疊影物件這樣的系統誤差(如Fig-04)。

Fig-04
訓練資料集
本次研究採用卷積神經網路中的Mask R-CNN 進行深度學習,使用來自Kaggle上提供的Airbus Ship Detection Challenge的圖像素材進行訓練,再以Sentinel-2 提供的高解析度遙測影像為檢測素材檢驗,是否有辦法進行船舶的目標物判釋。此資料集總共有473556幅衛星影像,網站上的分類將其中 457806 幅作為訓練集(Train Set),15750幅做為測試集(Test Set)。
Mask R-CNN模型訓練
訓練過程需耗費電腦大量運算及時間,不過 kaggle 網站會提供 30 40 hrs/week
不等的時間可以任意使用雲端GPU功能,因此Mask R-CNN模型訓練過程這部分是使用此雲端資源完成的。將 Mask R-CNN訓練10個循(epochs ),每循環約耗費
5-7小時左右,整個訓練過程約花3天完成,完成之後將模型之權重
(weights 保存下來進行接下來的測試。)
模型測試結果
為了評估Mask R-CNN 產出的高解析影像之成效,將Sentinel-2提供之衛星影像,其中包含1-5艘船隻之衛星影像各10幅,測試之結果如下圖。
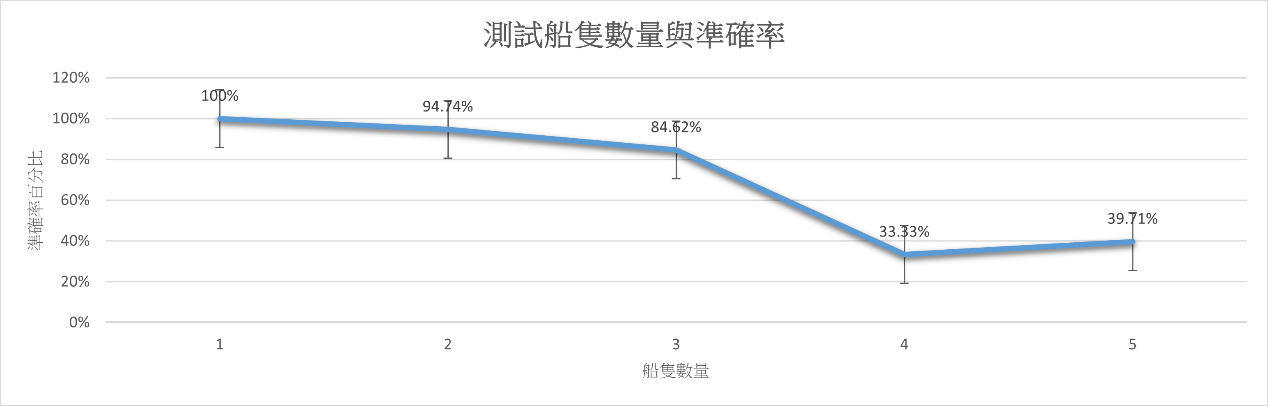
經過上述流程,花費數天的訓練,而將Mask R-CNN模型分別測試自身練集與Sentinel-2衛星影像的二種資料測試,驗證了其對辨識船隻目標有一定的學習能力。測試船隻數量大於3 時,平均精度相對1、2 較低,說明檢測網路對多目標的檢測還尚有可修正及提升的空間。
下一步將針對遙測影像中的多目標辨識進行研究,提升檢測網路對多目標的檢測能力。
總的來說,EDSREDSR在超解析成像中取得好的結果在超解析成像中取得好的結果,未來必定能大大增加應用性。